More layers
Contents
More layers¶
Two layers of neurons¶
In the previous chapter we have seen that the MCP neuron with the step activation function realizes the inequality \(x \cdot w=w_0+x_1 w_1 + \dots x_n w_n > 0\), where \(n\) in the dimensionality of the input space. It is instructive to follow up this geometric interpretation. Taking for definiteness \(n=2\) (the plane), the above inequality corresponds to a division into two half-planes. As we already know, the line given by the equation
is the dividing line.
Imagine now that we have more such conditions: two, three, etc., in general \(k\) independent conditions. Taking a conjunction of these conditions we can build regions as shown, e.g., in Fig. 7.
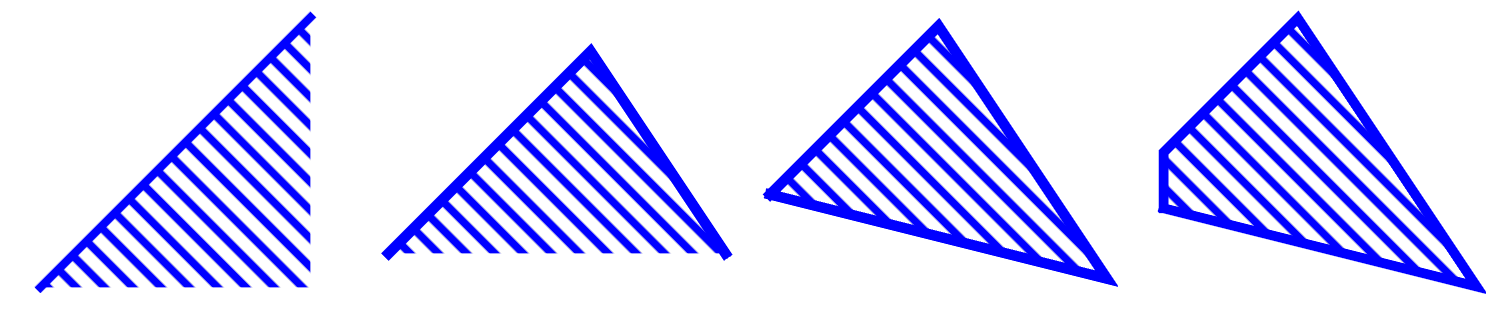
Fig. 7 Sample convex regions in the plane obtained, from left to right, with one inequality condition, and a conjunctions of 2, 3, or 4 inequality conditions, with the latter two yielding polygons.¶
Convex region
By definition, region \(A\) is convex if and only if a straight line between any two points in \(A\) is contained in \(A\). A region which is not convex is called concave.
Clearly, \(k\) inequality conditions can be imposed with \(k\) MCP neurons. Recall from section Boolean functions that we can straightforwardly build boolean functions with the help of the neural networks. In particular, we can make a conjunction of \(k\) conditions by taking a neuron with the weights \(w_0=-1\) and \(1/k < w_i < 1/(k-1)\), where \(i=1,\dots,k\). One possibility is, e.g.,
Indeed, let \(p_0=1\), and the conditions imposed by the inequalities be denoted as \(p_i\), \(i=1,\dots,k\), which may take values 1 or 0 (true or false). Then
if and only if all \(p_i=1\), i.e. all the conditions are true.
Architectures of networks for \(k=1\), 2, 3, or 4 conditions are shown in Fig. 8. Going from left to right from the second panel, we have networks with two layers of neurons and with \(k\) neurons in the intermediate layer, providing the inequality conditions, and one neuron in the output layer, acting as the AND gate. Of course, for one condition it is sufficient to have a single neuron, as shown in the left panel of Fig. 8.

Fig. 8 Networks capable of classifying data in the corresponding regions of Fig. 7.¶
In the geometric interpretation, the first neuron layer represents the \(k\) half-planes, and the neuron in the second layer correspond to a convex region with \(k\) sides.
The situation generalizes in an obvious way to data in more dimensions. In that case we have more black dots in the inputs in Fig. 8. Geometrically, for \(n=3\) we deal with dividing planes and convex polyhedrons, and for \(n>3\) with dividing hyperplanes and convex polytopes.
Note
If there are numerous neurons \(k\) in the intermediate layer, the resulting polygon has many sides which may approximate a smooth boundary, such as an arc. The approximation is better and better as \(k\) increases.
Important
A percepton with two neuron layers (with sufficiently many neurons in the intermediate layer) can classify points belonging to a convex region in \(n\)-dimensional space.
Three or more layers of neurons¶
We have just shown that a two-layer network may classify a convex polygon. Imagine now that we produce two such figures in the second layer of neurons, for instane as in the following network:
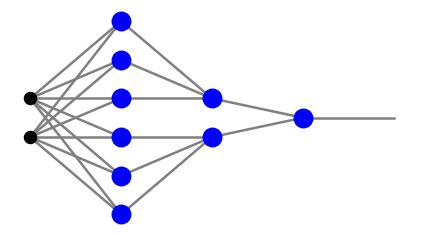
Note that the first and second neuron layers are not fully connected here, as we “stack on top of each other” two networks producing triangles, as in the third panel of Fig. 8. Next, in the third neuron layer (here having a single neuron) we implement a \(p \,\wedge \!\sim\!q\) gate, i.e. the conjunction of the conditions that the points belong to one triangle and do not belong to the other one. As we will show shortly, with appropriate weights, the above network may produce a concave region, for example a triangle with a triangular hollow:

Fig. 9 Triangle with a tringular hollow.¶
Generalizing this argument to other shapes, one can show an important theorem:
Important
A perceptron with three or more neuron layers (with sufficiently many neurons in intermediate layers) can classify points belonging to any region in \(n\)-dimensional space with \(n-1\)-dimensional hyperplane boundaries.
Note
It is worth stressing here that three layers provide full functionality! Adding more layers to a classifier does not increase its capabilities.
Feeding forward in Python¶
Before proceeding with an explicit example, we need a Python code for propagation of the signal in a general fully-connected feed-forward network. First, we represent the architecture of a network with \(l\) neuron layers as an array of the form
where \(n_0\) in the number of the input nodes, and \(n_i\) are the numbers of neurons in layers \(i=1,\dots,l\). For instance, the architecture of the network from the fourth panel of Fig. 8 is
arch=[2,4,1]
arch
[2, 4, 1]
In the codes of this course we use the convention of Fig. 5, namely, the bias is treated uniformly with the remaining signal. However, the bias notes are not included in counting the numbers \(n_i\) defined above. In particular, a more detailed view of the fourth panel of Fig. 8 is
plt.show(draw.plot_net(arch))
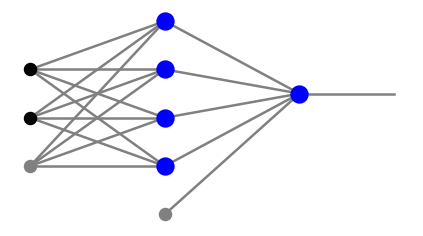
Here, black dots mean input, gray dots indicate the bias nodes carrying input =1, and the blue blobs are the neurons.
Next, we need the weights of the connections. There are \(l\) sets of weights, each one corresponding to the set of edges entering a given neuron layer from the left. In the above example, the first neuron layer (blue blobs to the left) has weights which form a \(3 \times 4\) matrix. Here 3 is the number of nodes in the preceding (input) layer (including the bias node) and 4 is the number of neurons in the first neuron layer. Similarly, the weights associated with the second (output) neuron layer form a \(4 \times 1\) matrix. Hence, in our convention, the weight matrices corresponding to subsequent neuron layers \(1, 2, \dots, l\) have dimensions
Thus, to store all the weights of a network we actually need three indices: one for the layer, one for the number of nodes in the preceding layer, and one for the number of nodes in the given layer. We could have used a three-dimensional array here, but since we number the neuron layers staring from 1, and arrays start numbering from 0, it is somewhat more convenient to use the Python dictionary structure. We then store the weights as
where \(arr^i\) is a two-dimensional array (matrix) of weights for the neuron layer \(i\). For the case of the above figure we can take, for instance
w={1:np.array([[1,2,1,1],[2,-3,0.2,2],[-3,-3,5,7]]),2:np.array([[1],[0.2],[2],[2],[-0.5]])}
print(w[1])
print("")
print(w[2])
[[ 1. 2. 1. 1. ]
[ 2. -3. 0.2 2. ]
[-3. -3. 5. 7. ]]
[[ 1. ]
[ 0.2]
[ 2. ]
[ 2. ]
[-0.5]]
For the signal propagating along the network we also correspondingly use a dictionary of the form
where \(x^0\) is the input, and \(x^i\) is the output leaving the neuron layer \(i\), with \(i=1, \dots, l\). All symbols \(x^j\), \(j=0, \dots, l\), are one-dimensional arrays. The bias nodes are included, hence the dimensions of \(x^j\) are \(n_j+1\), except for the output layer which has no bias node, hence \(x^l\) has the dimension \(n_l\). In other words, the dimensions of the signal arrays are equal to the total number of nodes in each layer.
Next, we present the corresponding formulas in a rather painful detail, as this is key to avoid any possible confusion related to the notation. We already know from (2) that for a single neuron with \(n\) inputs its incoming signal is calculated as
With more layers (labeled with superscript \(i\)) and neurons (\(n_i\) in layer \(i\)), the notation generalizes into
Note that the summation starts from \(\beta=0\) to account for the bias node in the preceding layer \((i-1)\), but \(\alpha\) starts from 1, as only neurons (and not the the bias node) in layer \(i\) receive the signal (see the figure below).
In the algebraic matrix notation, we can also write more compactly \(s^{iT} = x^{(i-1)T} W^i\), with \(T\) denoting transposition. Explicitly,
As we already know very well, the output from a neuron is obtained by acting on its incoming input with an activation function. Thus we finally have
with the bias nodes set to one. The figure below illustrates the notation.
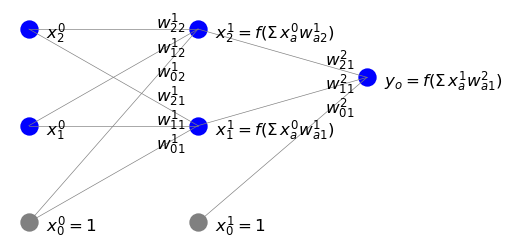
The implementation of the feed-forward propagation in Python is following:
def feed_forward(ar, we, x_in, f=func.step):
"""
Feed-forward propagation
input:
ar - array of numbers of nodes in subsequent layers [n_0, n_1,...,n_l]
(from input layer 0 to output layer l, bias nodes not counted)
we - dictionary of weights for neuron layers 1, 2,...,l in the format
{1: array[n_0+1,n_1],...,l: array[n_(l-1)+1,n_l]}
x_in - input vector of length n_0 (bias not included)
f - activation function (default: step)
return:
x - dictionary of signals leaving subsequent layers in the format
{0: array[n_0+1],...,l-1: array[n_(l-1)+1], l: array[nl]}
(the output layer carries no bias)
"""
l=len(ar)-1 # number of the neuron layers
x_in=np.insert(x_in,0,1) # input, with the bias node inserted
x={} # empty dictionary x
x.update({0: np.array(x_in)}) # add input signal to x
for i in range(1,l): # loop over layers except the last one
s=np.dot(x[i-1],we[i]) # signal, matrix multiplication
y=[f(s[k]) for k in range(arch[i])] # output from activation
x.update({i: np.insert(y,0,1)}) # add bias node and update x
# the output layer l - no adding of the bias node
s=np.dot(x[l-1],we[l]) # signal
y=[f(s[q]) for q in range(arch[l])] # output
x.update({l: y}) # update x
return x
For brevity, we adopt a convention where we do not pass the input bias node of the input in the argument. It is inserted inside the function with np.insert(x_in,0,1). As usual, we use np.dot for matrix multiplication.
Next, we test how feed_forward works on a sample input.
xi=[2,-1]
x=func.feed_forward(arch,w,xi,func.step)
print(x)
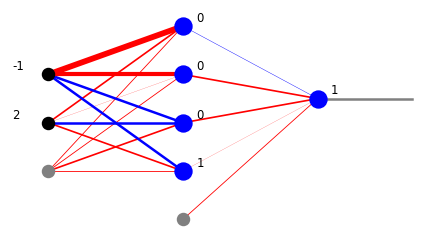
{0: array([ 1, 2, -1]), 1: array([1, 1, 0, 0, 0]), 2: [1]}
The output from this network is obtained as
x[2][0]
1
Digression on linear networks¶
Let us now make the following observation. Suppose we have a network with a linear activation function \(f(s)=c s\). Then the last formula from the feed-forward derivation becomes
or, in the matrix notation,
Iterating this, we get for the signal in the output layer
where \(W=c^l w^1 w^2 \dots w^l\). hence such a network is equivalent to a single-layer network with the weight matrix \(W\) as specified above.
Note
For that reason, it does not make sense to consider multiple layer networks with linear activation function.
Visualization¶
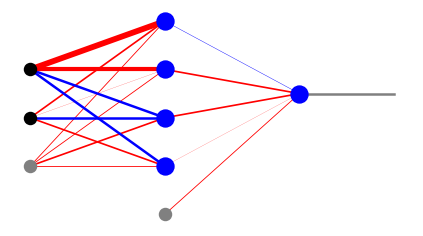
For visualization of simple networks, in the draw module of he neural library we provide some drawing functions which show the weights, as well as the signals. Function plot_net_w draws the positive weights in red and the negative ones in blue, with the widths reflecting their magnitude. The last parameter, here 0.5, rescales the widths such that the graphics looks nice. Function plot_net_w_x prints in addition the values of the signal leaving the nodes of each layer.
plt.show(draw.plot_net_w(arch,w,0.5))
plt.show(draw.plot_net_w_x(arch,w,0.5,x))
Classifier with three neuron layers¶
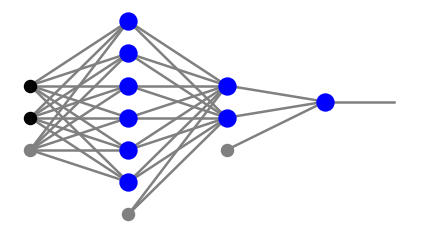
We are now ready to explicitly construct an example of a binary classifier of points in a concave region: a triagle with a triangular hollow of Fig. 9. The network architecture is
arch=[2,6,2,1]
plt.show(draw.plot_net(arch))
The geometric conditions and the corresponding weights for the first neuron layer are
\(\alpha\) |
inequality condition |
\(w_{0\alpha}^1\) |
\(w_{1\alpha}^1\) |
\(w_{2\alpha}^1\) |
|---|---|---|---|---|
1 |
\(x_1>0.1\) |
-0.1 |
1 |
0 |
2 |
\(x_2>0.1\) |
-0.1 |
0 |
1 |
3 |
\(x_1+x_2<1\) |
1 |
-1 |
-1 |
4 |
\(x_1>0.25\) |
-0.25 |
1 |
0 |
5 |
\(x_2>0.25\) |
-0.25 |
0 |
1 |
6 |
\(x_1+x_2<0.8\) |
0.8 |
-1 |
-1 |
Conditions 1-3 provide boundaries for the bigger triangle, and 4-6 for the smaller one contained in the bigger one. In the second neuron layer we need to realize two AND gates for conditions 1-3 and 4-6, respectively, hence we take
\(\alpha\) |
\(w_{0\alpha}^2\) |
\(w_{1\alpha}^2\) |
\(w_{2\alpha}^2\) |
\(w_{3\alpha}^2\) |
\(w_{4\alpha}^2\) |
\(w_{5\alpha}^2\) |
\(w_{6\alpha}^2\) |
|---|---|---|---|---|---|---|---|
1 |
-1 |
0.4 |
0.4 |
0.4 |
0 |
0 |
0 |
2 |
-1 |
0 |
0 |
0 |
0.4 |
0.4 |
0.4 |
Finally, in the output layer we take the \(p \wedge \! \sim \! q\) gate, hence
\(\alpha\) |
\(w_{0\alpha}^3\) |
\(w_{1\alpha}^3\) |
\(w_{2\alpha}^3\) |
|---|---|---|---|
1 |
-1 |
1.2 |
-0.6 |
Putting all this together, the weight dictionary is
w={1:np.array([[-0.1,-0.1,1,-0.25,-0.25,0.8],[1,0,-1,1,0,-1],[0,1,-1,0,1,-1]]),
2:np.array([[-1,-1],[0.4,0],[0.4,0],[0.4,0],[0,0.4],[0,0.4],[0,0.4]]),
3:np.array([[-1],[1.2],[-0.6]])}
Feeding forward a sample input yields
xi=[0.2,0.3]
x=func.feed_forward(arch,w,xi)
plt.show(draw.plot_net_w_x(arch,w,1,x))
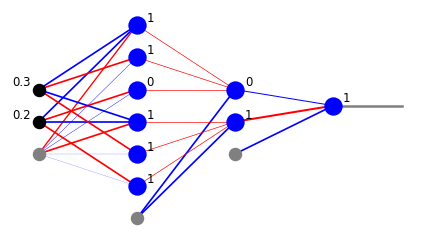
We have just found that point [0.2,0.3] is within our region (1 from the output layer). Actually, we we have more information from the intermediate layers. From the second neuron layer we know that the point belongs to the bigger triangle (1 from the lower neuron) and does not belong to the smaller triangle (0 from the upper neuron). From the first neuron layer we may read out the conditions from the six inequalities.
Next, we test how our network works for other points. First, we define a function generating a random point in the square \([0,1]\times [0,1]\) and pass it through the network. We assign to it label 1 if it belongs to the requested triangle with the hollow, and 0 otherwise. Subsequently, we create a large sample of such points and generate the graphics, using pink for label 1 and blue for label 0.
def po():
xi=[np.random.random(),np.random.random()] # random point from the [0,1]x[0,1] square
x=func.feed_forward(arch,w,xi) # feed forward
return [xi[0],xi[1],x[3][0]] # the point's coordinates and label
samp=np.array([po() for _ in range(10000)])
print(samp[:5])
[[0.71435539 0.05281912 0. ]
[0.54490285 0.59347251 0. ]
[0.95485103 0.77741598 0. ]
[0.71722458 0.42208055 0. ]
[0.54892879 0.62149029 0. ]]
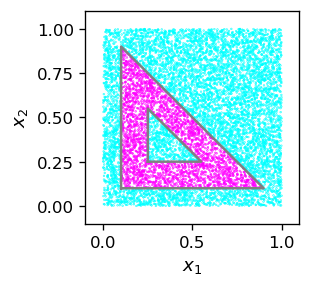
We can see that our little machine works perfectly well!
At this point the reader might rightly say that the preceding results are trivial: in essence, we have just been implementing some geometric conditions and their conjunctions.
However, as in the case of single-layer networks, there is an important argument against this apparent triviality. Imagine again we have a data sample with labels, and only this, as in the example of the single MCP neuron of chapter MCP Neuron. Then we do not have the dividing conditions to begin with and need some efficient way to find them. This is exactly what teaching of classifiers will do: its sets the weights in such a way that the proper conditions are implicitly built in. After the material of this chapter, the reader should be convinced that this is perfectly possible and there is nothing magical about it! In the next chapter we will show how to do it.
Exercises¶
\(~\)
Design a network and run the code from this lecture for a convex region of your choice.
Design and program a classifier for four categories of points belonging to regions formed by 2 intersecting lines (hint: include four output cells).