Rectification
Contents
Rectification¶
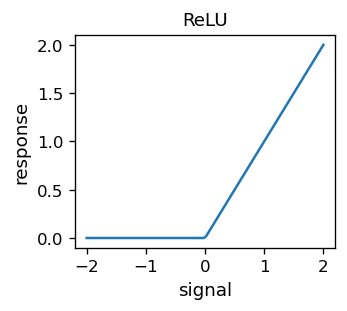
In the previous chapter we made a hump function from two sigmoids, which would form a basis function for approximation. We may now ask a follow-up question: can we make the sigmoid itself a linear combination (or simply difference) of some other functions. Then we could use these functions for activation of neurons in place of the sigmoid. The answer is yes. For instance, the Rectified Linear Unit (ReLU) function
does (approximately) the job. The somewhat awkward name comes from electonics, where a “rectifying” (straightening up) unit is used to cut off negative values of an electric signal. The plot of ReLU looks as follows:
Taking a difference of two ReLU functions with shifted arguments yields, for example,
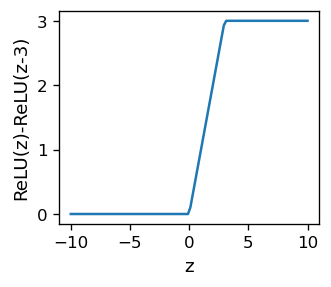
which looks pretty much as a sigmoid, apart from the sharp corners. One can make things smooth by taking a different function, the softplus,
which looks like
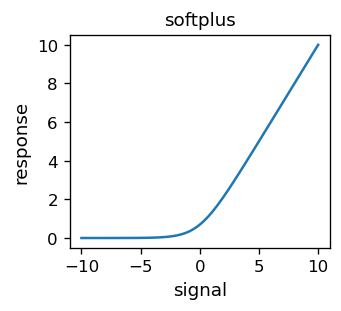
A difference of two softplus functions yields a result very similar to the sigmoid.
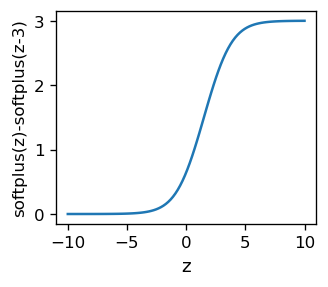
Note
One may use the ReLU of softplus, or a plethora of other similar functions, for the activation.
Why one should actually do this will be dicussed later.
Interpolation with ReLU¶
We can approximate our simulated data with an ANN with ReLU acivation in the intermediate layers (and the identity function is the output layer, as in the previous section). The functions are taken from the module func.
fff=func.relu # short-hand notation
dfff=func.drelu
The network must now have more neurons, as the sigmoid “splits” into two ReLU functions:
arch=[1,30,1] # architecture
weights=func.set_ran_w(arch, 5) # initialize weights randomly in [-2.5,2.5]
We carry the simulations exactly as in the previous case. Experience says one should stat with small learning speeds. Two sets of rounds (as in the previous chapter)
eps=0.0003 # small learning speed
for k in range(30): # rounds
for p in range(len(features)): # loop over the data sample points
pp=np.random.randint(len(features)) # random point
func.back_prop_o(features,labels,pp,arch,weights,eps,
f=fff,df=dfff,fo=func.lin,dfo=func.dlin) # teaching
for k in range(600): # rounds
eps=eps*.995
for p in range(len(features)): # points in sequence
func.back_prop_o(features,labels,p,arch,weights,eps,
f=fff,df=dfff,fo=func.lin,dfo=func.dlin) # teaching
yield the result
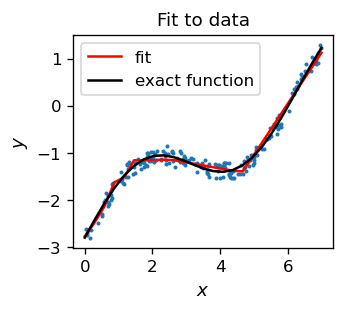
We obtain again a quite satisfactory result (red line), noticing that the plot of the fitting function is a sequence of straight lines, simply reflecting the features of the ReLU activation function.
Classifiers with rectification¶
There are technical reasons in favor of using rectified functions rather than sigmoid-like ones in backprop. The derivatives of the sigmoid are very close to zero apart for the narrow region near the threshold. This makes updating the weights unlikely, especially when going many layers back, as then very small numbers multiply yielding essentially no update (this is known as the vanishing gradient problem). With rectified functions, the range where the derivative is large is big (for ReLU it holds for all positive coordinates), hence the problem is cured. For that reason, rectified functions are used in deep ANNs, where there are many layers, impossible to train when the activation function is of a sigmoid type.
Note
Application of rectified activation functions was one of the key tricks that allowed a breakthrough in deep ANNs around 2011.
On the other hand, with ReLU it may happen that some weights are set to such values that many neurons become inactive, i.e. never fire for any input, and so are effectively eliminated. This is known as the “dead neuron” or “dead body” problem, which arises especially when the learning speed parameter is too high. A way to reduce the problem is to use an activation function which does not have at all a range with zero derivative, such as the Leaky ReLU. Here we take it in the form
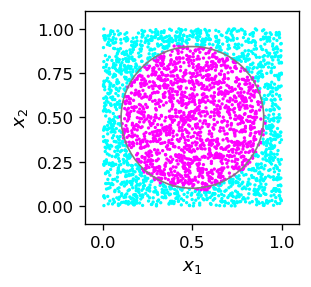
For illustration, we repeat our example from section Example with the circle with the classification of points in the circle, now with Leaky ReLU.
We take the following architecture and initial parameters:
arch_c=[2,20,1] # architecture
weights=func.set_ran_w(arch_c,3) # scaled random initial weights in [-1.5,1.5]
eps=.01 # initial learning speed
and run the algorithm in two stages: with Leaky ReLU, and then with ReLU.
for k in range(300): # rounds
eps=.9999*eps # decrease the learning speed
if k%100==99: print(k+1,' ',end='') # print progress
for p in range(len(features_c)): # loop over points
func.back_prop_o(features_c,labels_c,p,arch_c,weights,eps,
f=func.lrelu,df=func.dlrelu,fo=func.sig,dfo=func.dsig)
# backprop with leaky ReLU
100 200 300
for k in range(700): # rounds
eps=.9999*eps # decrease the learning speed
if k%100==99: print(k+1,' ',end='') # print progress
for p in range(len(features_c)): # loop over points
func.back_prop_o(features_c,labels_c,p,arch_c,weights,eps,
f=func.relu,df=func.drelu,fo=func.sig,dfo=func.dsig)
# backprop with ReLU
100 200 300 400 500 600 700
The result is quite satisfactory, showing that the method works. With the present architecture and activation functions, not surprisingly, in the plot below we can notice traces of a polygon approximating the circle.
Exercises¶
\(~\)
Use various rectified activation functions for the binary classifiers and test them on various shapes (in analogy to the example with the circle above).
Convince yourself that starting backprop (with ReLU) with a too large initial learning speed leads to a “dead neuron” problem and a failure of the algorithm.